
※こちらはQiitaの投稿記事の一部修正版です。
※Qiita投稿記事はこちら
※記事内で動かない・間違い箇所などありましたら是非教えて下さい!
こちらは前回の記事の続きです。
下準備まではコチラをご覧ください。
記事の概要
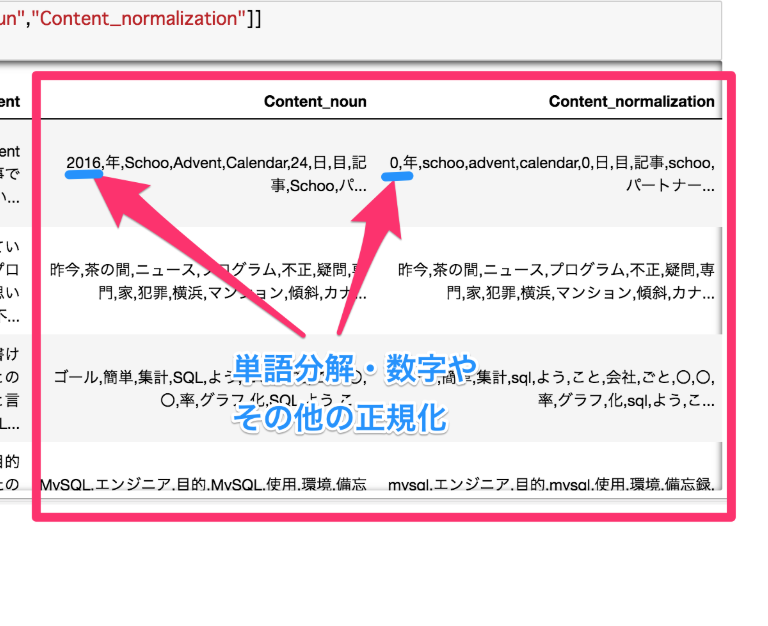
前回は、169ページ分、1682個の「非エンジニア」記事を取ってきて、タイトル・本文・その他のデータフレームを作りました。
また単語に分解し、数字など不要なものを綺麗にしました。
この記事では、記事本文データを使ってLDAでいくつかのトピックに分けていこうと思います。
先に書いておくと、最初scikit-learnのLDAを使ったのですが、100記事以上が重くて動かず・・・コチラのldaを使いました。
https://pypi.org/project/lda/
まずはscikit-learnのLDAを動かしてみる
まずは途中で動かなくなったscikit-learnから。
|
1 2 3 4 |
<span class="c">#必要なライブラリをimport</span> <span class="kn">from</span> <span class="nn">sklearn.feature_extraction.text</span> <span class="kn">import</span> <span class="n">CountVectorizer</span><span class="p">,</span> <span class="n">TfidfVectorizer</span> <span class="kn">from</span> <span class="nn">sklearn.decomposition</span> <span class="kn">import</span> <span class="n">LatentDirichletAllocation</span> <span class="kn">import</span> <span class="nn">joblib</span> |
|
1 2 3 4 |
<span class="c">#文章×単語行列に変換</span> <span class="n">vectorizer</span> <span class="o">=</span> <span class="n">CountVectorizer</span><span class="p">(</span><span class="n">token_pattern</span><span class="o">=</span><span class="s">r"(?u)\b\w+\b"</span><span class="p">)</span> <span class="c">#訓練データ用にBow表現に。</span> <span class="n">X</span> <span class="o">=</span> <span class="n">vectorizer</span><span class="o">.</span><span class="n">fit_transform</span><span class="p">(</span><span class="n">df</span><span class="p">[</span><span class="s">"Content_normalization"</span><span class="p">])</span> |
↑ここでdf[“Content_normalization”]とありますが、僕のPCだとdfは100記事までしか動きませんでした!なので、ここのdfは縮小版です。
|
1 2 3 4 |
<span class="c">#単語番号と単語を紐づけ</span> <span class="n">index2word</span> <span class="o">=</span> <span class="p">{}</span> <span class="k">for</span> <span class="n">word</span><span class="p">,</span> <span class="n">word_id</span> <span class="ow">in</span> <span class="n">tqdm</span><span class="p">(</span><span class="n">vectorizer</span><span class="o">.</span><span class="n">vocabulary_</span><span class="o">.</span><span class="n">items</span><span class="p">()):</span> <span class="n">index2word</span><span class="p">[</span><span class="n">word_id</span><span class="p">]</span> <span class="o">=</span> <span class="n">word</span> |
|
1 2 3 |
<span class="c">#3分類でインスタンス作成。モデルの作成</span> <span class="n">lda</span> <span class="o">=</span> <span class="n">LatentDirichletAllocation</span><span class="p">(</span><span class="n">n_components</span><span class="o">=</span><span class="mi">3</span><span class="p">,</span> <span class="n">n_jobs</span><span class="o">=-</span><span class="mi">1</span><span class="p">,</span> <span class="n">verbose</span><span class="o">=</span><span class="mi">1</span><span class="p">)</span> <span class="n">X_transformed</span> <span class="o">=</span> <span class="n">lda</span><span class="o">.</span><span class="n">fit_transform</span><span class="p">(</span><span class="n">X</span><span class="p">)</span> |
|
1 2 3 4 5 6 7 8 9 |
<span class="c">#各トピックの特徴単語を抽出</span> <span class="k">for</span> <span class="n">t</span> <span class="ow">in</span> <span class="nb">range</span><span class="p">(</span><span class="n">lda</span><span class="o">.</span><span class="n">n_components</span><span class="p">):</span> <span class="c"># トピック t における、単語の出現確率を lda.components_[t] で取得</span> <span class="c"># np.argsort で昇順に並び替えた順の index を取得、[::-1] で降順に並び替え</span> <span class="n">indices</span> <span class="o">=</span> <span class="n">np</span><span class="o">.</span><span class="n">argsort</span><span class="p">(</span><span class="n">lda</span><span class="o">.</span><span class="n">components_</span><span class="p">[</span><span class="n">t</span><span class="p">])[::</span><span class="o">-</span><span class="mi">1</span><span class="p">]</span> <span class="k">print</span><span class="p">(</span><span class="s">"Topic #{} ----------------------------------------"</span><span class="o">.</span><span class="n">format</span><span class="p">(</span><span class="n">t</span><span class="o">+</span><span class="mi">1</span><span class="p">))</span> <span class="k">for</span> <span class="n">word_id</span> <span class="ow">in</span> <span class="n">indices</span><span class="p">[:</span><span class="mi">10</span><span class="p">]:</span> <span class="k">print</span><span class="p">(</span><span class="n">index2word</span><span class="p">[</span><span class="n">word_id</span><span class="p">])</span> <span class="k">print</span><span class="p">()</span> |
▼JupyterNotebook

うーん。という感じですね。
考えるに、下記の順でパッとしない原因と対策があると思っています。
・「ため」などの無駄なものが多い。ストップワードで単語データを綺麗にする
・データ数が100記事しか食わせてないので少ない
・カテゴリ数が微妙。変えてみる
・そもそも綺麗に分かれるはずがない?
・そもそもなにか手順が変?
とりあえずこのまま、タイトル分類も見てみます。
|
1 2 3 4 5 6 7 8 9 |
<span class="k">for</span> <span class="n">t</span> <span class="ow">in</span> <span class="nb">range</span><span class="p">(</span><span class="n">lda</span><span class="o">.</span><span class="n">n_components</span><span class="p">):</span> <span class="c"># トピック t を軸に切り出す</span> <span class="c"># np.argsort で昇順に並び替えた順の index を取得、[::-1] で降順に並び替え</span> <span class="n">indices</span> <span class="o">=</span> <span class="n">np</span><span class="o">.</span><span class="n">argsort</span><span class="p">(</span><span class="n">X_transformed</span><span class="p">[:,</span><span class="n">t</span><span class="p">])[::</span><span class="o">-</span><span class="mi">1</span><span class="p">]</span> <span class="k">print</span><span class="p">(</span><span class="s">"Topic #{} ----------------------------------------"</span><span class="o">.</span><span class="n">format</span><span class="p">(</span><span class="n">t</span><span class="p">))</span> <span class="k">for</span> <span class="n">document_id</span> <span class="ow">in</span> <span class="n">indices</span><span class="p">[:</span><span class="mi">10</span><span class="p">]:</span> <span class="k">print</span><span class="p">(</span><span class="n">df</span><span class="o">.</span><span class="n">iloc</span><span class="p">[</span><span class="n">document_id</span><span class="p">][</span><span class="s">"Title"</span><span class="p">])</span> <span class="k">print</span><span class="p">()</span> |
▼JupyterNotebook

なんとなく、トピック0:教育、トピック1:実用、トピック2:その他、という感じで分かれている、と言われればそう見えなくもないような、どうなんだろう・・・。
次はldaを使ってみる
|
1 2 3 |
<span class="c">#ライブラリのimport</span> <span class="kn">import</span> <span class="nn">lda</span> <span class="kn">import</span> <span class="nn">lda.datasets</span> |
|
1 2 3 4 |
<span class="c">#インスタンスなど</span> <span class="n">X</span> <span class="o">=</span> <span class="n">lda</span><span class="o">.</span><span class="n">datasets</span><span class="o">.</span><span class="n">load_reuters</span><span class="p">()</span> <span class="n">vocab</span> <span class="o">=</span> <span class="n">lda</span><span class="o">.</span><span class="n">datasets</span><span class="o">.</span><span class="n">load_reuters_vocab</span><span class="p">()</span> <span class="n">titles</span> <span class="o">=</span> <span class="n">lda</span><span class="o">.</span><span class="n">datasets</span><span class="o">.</span><span class="n">load_reuters_titles</span><span class="p">()</span> |
|
1 2 |
<span class="c">#上のscikit-learnで作った単語行列から、欲しいモノを取ってくる。</span> <span class="n">vect</span> <span class="o">=</span> <span class="n">vectorizer</span><span class="o">.</span><span class="n">get_feature_names</span><span class="p">()</span> |
|
1 2 3 |
<span class="c">#3分類でモデルの生成</span> <span class="n">model</span> <span class="o">=</span> <span class="n">lda</span><span class="o">.</span><span class="n">LDA</span><span class="p">(</span><span class="n">n_topics</span><span class="o">=</span><span class="mi">3</span><span class="p">,</span> <span class="n">n_iter</span><span class="o">=</span><span class="mi">1500</span><span class="p">,</span> <span class="n">random_state</span><span class="o">=</span><span class="mi">1</span><span class="p">,</span> <span class="n">alpha</span> <span class="o">=</span> <span class="mi">10</span><span class="p">)</span> <span class="n">model</span><span class="o">.</span><span class="n">fit</span><span class="p">(</span><span class="n">X</span><span class="p">)</span> <span class="c"># model.fit_transform(X) is also available</span> |
|
1 2 3 4 5 6 7 |
<span class="c">#単語抽出</span> <span class="k">for</span> <span class="n">t</span> <span class="ow">in</span> <span class="nb">range</span><span class="p">(</span><span class="n">model</span><span class="o">.</span><span class="n">n_topics</span><span class="p">):</span> <span class="n">indices</span> <span class="o">=</span> <span class="n">np</span><span class="o">.</span><span class="n">argsort</span><span class="p">(</span><span class="n">model</span><span class="o">.</span><span class="n">topic_word_</span><span class="p">[</span><span class="n">t</span><span class="p">])[::</span><span class="o">-</span><span class="mi">1</span><span class="p">]</span> <span class="k">print</span><span class="p">(</span><span class="s">"Topic #{} ----------------------------------------"</span><span class="o">.</span><span class="n">format</span><span class="p">(</span><span class="n">t</span><span class="o">+</span><span class="mi">1</span><span class="p">))</span> <span class="k">for</span> <span class="n">word_id</span> <span class="ow">in</span> <span class="n">indices</span><span class="p">[:</span><span class="mi">10</span><span class="p">]:</span> <span class="k">print</span><span class="p">(</span><span class="n">index2word</span><span class="p">[</span><span class="n">word_id</span><span class="p">])</span> <span class="k">print</span><span class="p">()</span> |
あれ、、、アルファベット順?笑
ちょっと並べ替えが上手くいっていないですが、タイトル分類にいきます。

|
1 2 3 4 5 6 7 8 |
<span class="n">doc_topic</span> <span class="o">=</span> <span class="n">model</span><span class="o">.</span><span class="n">doc_topic_</span> <span class="k">for</span> <span class="n">t</span> <span class="ow">in</span> <span class="nb">range</span><span class="p">(</span><span class="n">model</span><span class="o">.</span><span class="n">n_topics</span><span class="p">):</span> <span class="n">indices</span> <span class="o">=</span> <span class="n">np</span><span class="o">.</span><span class="n">argsort</span><span class="p">(</span><span class="n">doc_topic</span><span class="p">[:,</span><span class="n">t</span><span class="p">])[::</span><span class="o">-</span><span class="mi">1</span><span class="p">]</span> <span class="k">print</span><span class="p">(</span><span class="s">"Topic #{} ----------------------------------------"</span><span class="o">.</span><span class="n">format</span><span class="p">(</span><span class="n">t</span><span class="p">))</span> <span class="k">for</span> <span class="n">document_id</span> <span class="ow">in</span> <span class="n">indices</span><span class="p">[:</span><span class="mi">10</span><span class="p">]:</span> <span class="k">print</span><span class="p">(</span><span class="n">df</span><span class="o">.</span><span class="n">iloc</span><span class="p">[</span><span class="n">document_id</span><span class="p">][</span><span class="s">"Title"</span><span class="p">])</span> <span class="k">print</span><span class="p">()</span> |

これはなかなかいい感じ・・・ですね!?笑
トピック0は考え方や言葉でのまとめ系、トピック1は挑戦してみた系の技術記事、トピック2は解説系(教える感じ)の技術記事、と分かれているように、僕は見えます!!笑
このニュアンス感がLDAっぽい…?
改善策
今回はとりあえずアウトプットを出してみましたが、前述した通り、下記の方法でもうちょっと改善しそうです。
- ストップワードなど、もっと単語データを綺麗にする
- カテゴリ数やその他オプション値を変えてみる
この記事は単純にLDAを使ってみたかった。という気持ちが先行しましたが、「非エンジニア」記事と他記事と比較・クラスタリングなどするともうちょっと何か見えそうです。記事自体はけっこうあったので、また手が空いた時に、単語ベースでの特徴抽出や、時系列で記事遷移やいいね数などを追ってみようかと思います。
※コードはサポートページや本などから持ってきている部分が多く、完全に理解できていない部分もあります。「もっとこうしたら良い」「ここいらない」など是非教えて下さい!
コメントを残す